In this post I wanted to explore how you can accelerate file storage (using CIFS as an example) over a wide area network and why it traditionally does not work for block storage (using iSCSI as an example). First let’s look into some of the (greatly simplified) common differences between the types of storage.
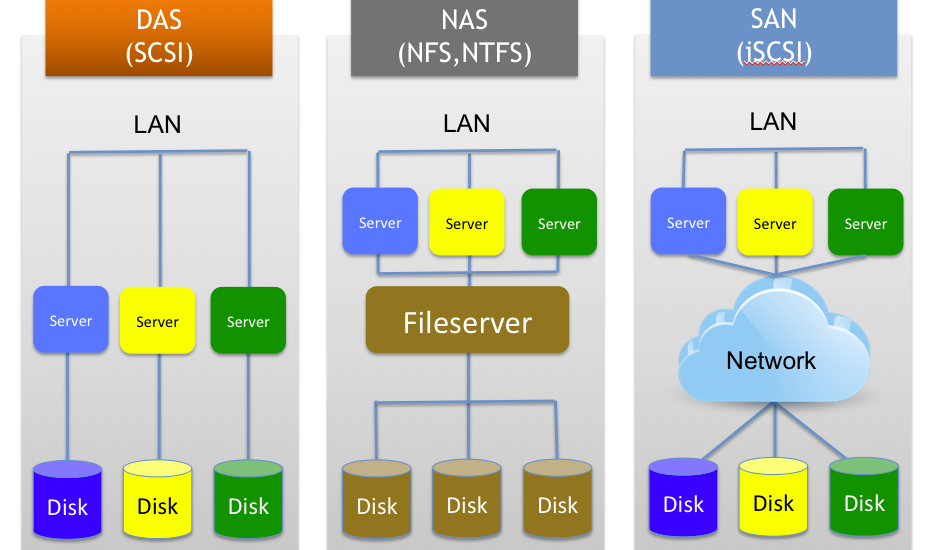
On the left side we have direct attached storage, or DAS, which are hard disks directly attached (using an internal SCSI controller) to each server, each server has it’s own disk. In the middle we have file storage whereby a fileserver (NAS) that has direct attached storage internally, presents this storage externally via a file storage protocol (NFS or CIFS in this case). The external servers or clients access the shared storage over the LAN network. Underneath the filesystem sits block based storage. On the right side we have a storage area network, or SAN, which carves out logical storage partitions (LUNs) and assigns them to each server using a block storage protocol (iSCSI in this case). The external server is the sole owner of his own LUN, typically connecting via a storage VLAN (iSCSI) of fibre channel (FC) network to the block storage system. So user file access happens through a file system, certain applications are installed on top of a file system (installing Firefox on top of NTFS on your Windows 7 PC for example) and other applications are installed directly onto block storage (installing MS-SQL server on a raw LUN for example).
Accelerating CIFS over a WAN
CIFS is an application protocol that generates a lot of chattiness (round trips) with standard usage, in a LAN environment the effects of this are negligible, but over a WAN each round trip significantly slows down the application performance. If you add too much latency into the mix above you will likely run into performance issues, or in the case of block storage, it will simply not work at all. For CIFS we are able to do certain things using WAN acceleration technology that help mitigate the chattiness issue. One of the techniques we can use is CIFS read-ahead. Traditionally CIFS will ask (read) small portions of a given file at once (usually 4KB increments), if you generate reads over a WAN connection (latency) to read an entire file like this you have a lot of round trips. As an example if you have a 100MB file you would generate 25000 read requests over the WAN each being impacted by the round trip latency. With CIFS read ahead we can intelligently ask (read) bigger portions of the file (combine read requests into a single request) as to minimize the round trip latency effect. This works because a file on a filesystem is continues (we know the beginning, size, and end of the file), this allows us to predict what the client will ask next and provide the data in as little requests as possible.
Accelerating block storage over a WAN
A file is made up of a certain number of storage blocks, these storage block are randomly stored on the storage system, traditionally there is no way to predict which blocks are needed for any given file being requested over the WAN connection. When an application requests blocks it assumes these are available from a fast (low latency) storage system. So in oder to accelerate the blocks needed for any given file being requested, we need to predict which blocks make up which files, so when a user/application requests a file over the WAN, the blocks are available locally (low latency). This is where the “magic” of Riverbed Granite comes into play, Granite can predict the blocks that make up files and makes sure these block are available locally, in a local block cache, when needed. In order to predict the linkage between files and blocks we need to understand the filesystem, today Granite supports NTFS and VMFS in this prediction method, if you need something else, for example you want to run a MS SQL database on local block storage we can also facilitate that by caching the entire LUN locally (and asynchronously syncing it back to the SAN in the datacenter).