In februari of 2018 Rubrik announced the acquisition of Datos IO, a startup with a focus on data management for an underserved part of the market namely (a.o.) NoSQL databases like Cassandra and MongoDB. Before jumping into more specifics about what Rubrik Datos IO is enabling for NoSQL databases, let’s first talk about the concept of these types of databases using MongoDB as an example.
The name MongoDB is derived from the term huMONGOus, a nod to the capability of NoSQL DB’s to handle large amounts of information.
NoSQL gained popularity through the needs of large webscale players like Facebook and Google which could no longer be easily met by traditional RDBMS (NoSQL referring to “non-relational” as opposed to the R in RDBMS) systems like Oracle and MS SQL. They required more flexible data models and needed to be able to serve extremely large amounts of incoming data from application users around the world whilst maintaining consistent performance and reliability.
Note: besides relational databases there are others as well, including Columnar (HBase), Graph (Neo4j), Key-value (Redis), etc.
MongoDB uses yet another variant called a document-based data model, meaning that you can sort of put anything you want into MongoDB as long as you follow it’s JSON (as it’s standard object type) like document style. You don’t need to use the same schema across different documents, you can have different fields in every document, and there is also no need to have a single key value (this is for example different in Cassandra), it does however automatically apply a unique object id (“_id”) to each document. This translates to a lot of flexibility overall. Today the use of NoSQL has gone beyond the large webscale players and infiltrated start-ups (with ambitions of becoming the next Facebook) and indeed also enterprise environments (it could possibly sometimes be debatable if the RDBMS route wouldn’t suffice in some of these cases but that is another discussion).
NoSQL, Cap theorem, and ACID transactions
CAP (Consistency, Availability, and Partition-tolerance) theorem determines how distributed database systems behave in the face of network instability. The database can be Consistent, meaning writes are atomic (transactions either execute in full or do not execute at all) and when you read data after the write the value is the last write. The database can be Available, meaning you will get a value back as long as a single node is operational. And/or the database can be Partition-tolerant, meaning operational even when communication is (temporarily) lost between the nodes. Cap theorem states however that at most two of these are applicable at once, and never all three.
Note: there are claims of potentially achieving all three at once, as in the case of this research paper on Google Spanner.
ACID (Atomicity, Consistency, Isolation, Durability) then, is a set of properties of database transactions intended to guarantee validity even in the event of errors, power failures, etc.
Many NoSQL stores compromise consistency (as used in CAP) in favor of availability, partition-tolerance, and speed. Most NoSQL stores also lack true ACID transactions. Instead, most NoSQL databases offer a concept of “eventual consistency” in which database changes are propagated to all nodes “eventually” (typically within milliseconds) so queries for data might not return updated data immediately or might result in reading data that is not accurate, a problem known as stale reads.
MongoDB falls in the consistency and partition-tolerance spectrum of CAP preferring consistency over availability by using a single master design, meaning that if the master is down the database is unavailable for whilst a new master is elected.
MongoDB Architecture
MongoDB uses the concepts of databases, collections (traditionally tables), and documents (traditionally rows).
As mentioned before MongoDB uses a single master architecture, preferring consistency over availability, but you can use secondaries which maintain backup copies of your master database instance. These are managed using replica sets, when writes come into the primary these are replicated using an operation log (Oplog) to the secondary nodes (which can be spread across datacenter locations). When the primary goes down the secondaries can elect a new primary within seconds (all the while data is available as read-only) with the understanding that you need a majority vote to make this happen. Replica sets are meant to address durability, not scalability (i.e. you shouldn’t really read from your secondary nodes). To address scalability we need to look at sharding whereby you have multiple replica sets (combination of a primary plus a bunch of secondary nodes) with each replica set being responsible for a range of indices. In other words for this to work you need to have a way to use an index in the first place so you need to build that (index based on some unique value) into your data model somehow. From the point of view of your application server you need to use a set of routers (mongos) that talk to 3 config servers and then point you to the correct replica set. MongoDB mongos instances route queries and write operations to shards in a sharded cluster. mongos provide the only interface to a sharded cluster from the perspective of applications. Applications never connect or communicate directly with the shards.
Next-Generation Backup and Recovery for MongoDB
Rubrik Datos IO is meant to facilitate application-consistent backup, point-in-time recovery, and deduplication for sharded and unsharded MongoDB clusters and geo-distributed MongoDB deployments.
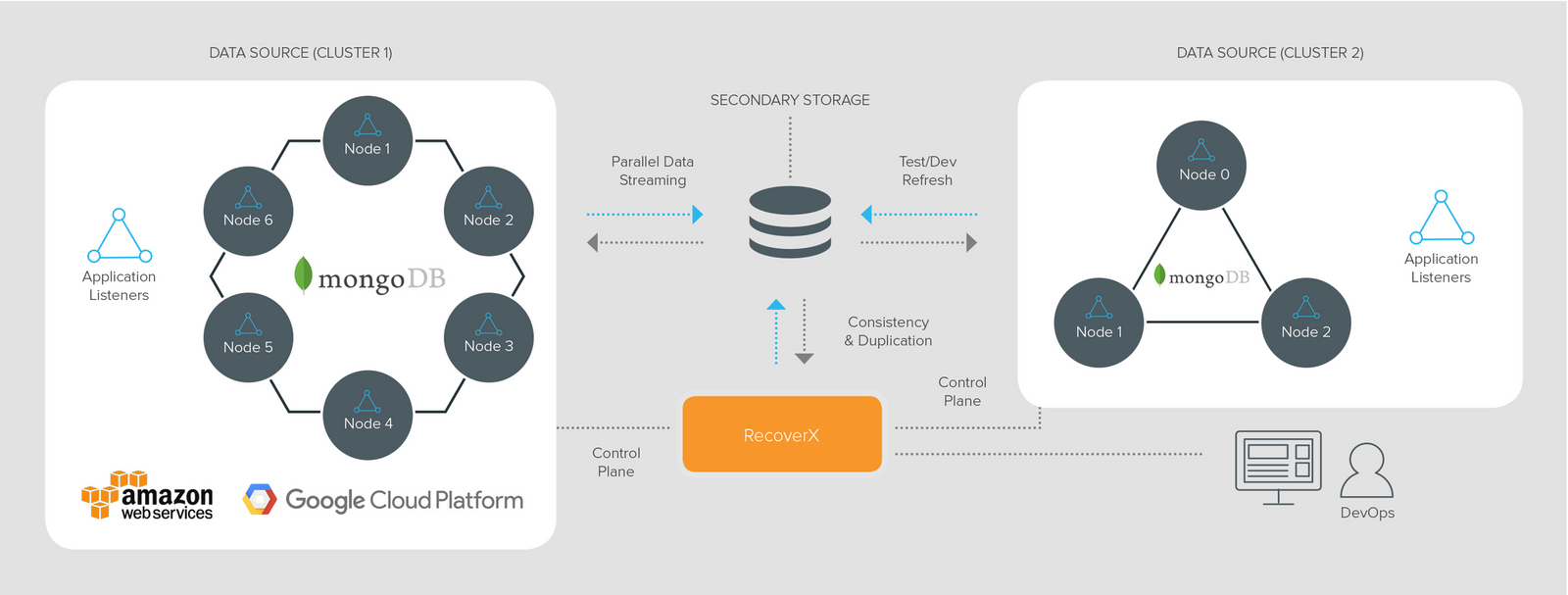
The solution is called RecoverX which is a scale-out data protection software that acts as the control plane to move backup data between your production MongoDB environment and a secondary storage location. It performs continuous backups using the Oplog’s, it streams data in parallel from multiple MongoDB nodes. It also semantically deduplicates files across the MongoDB cluster in order to only store only one instance of the data if you are backing up to different directories but is simultaneously tracked in a metadata map for recovery.
RecoverX workflow
The workflow of backing up your MongoDB data is based on a policy in which you select the datasource (MongoDB or others), select the specific MongoDB cluster and version store (secondary storage location), which specific database(s) you want to protect and a schedule that defines RPO/RTO values.
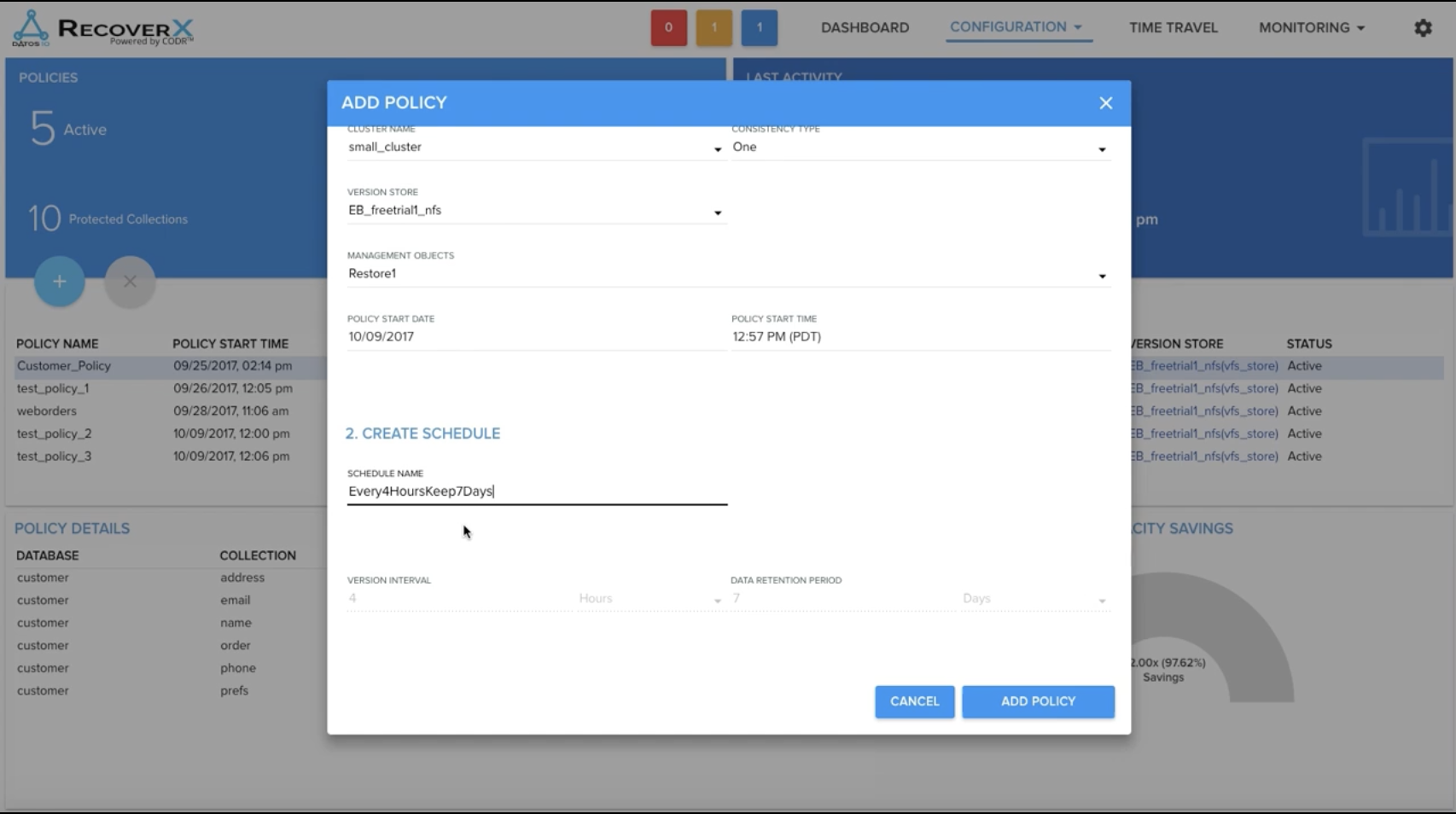
Once the policy is added the first full backup is triggered, this happens without quiescing the database.
Recovering data works via the Time Travel tab which allows you to select the directories to recover and see it’s available timestamps. Orchestrated recovery then allows you to select the MongoDB destination cluster, database, and collection to restore to.
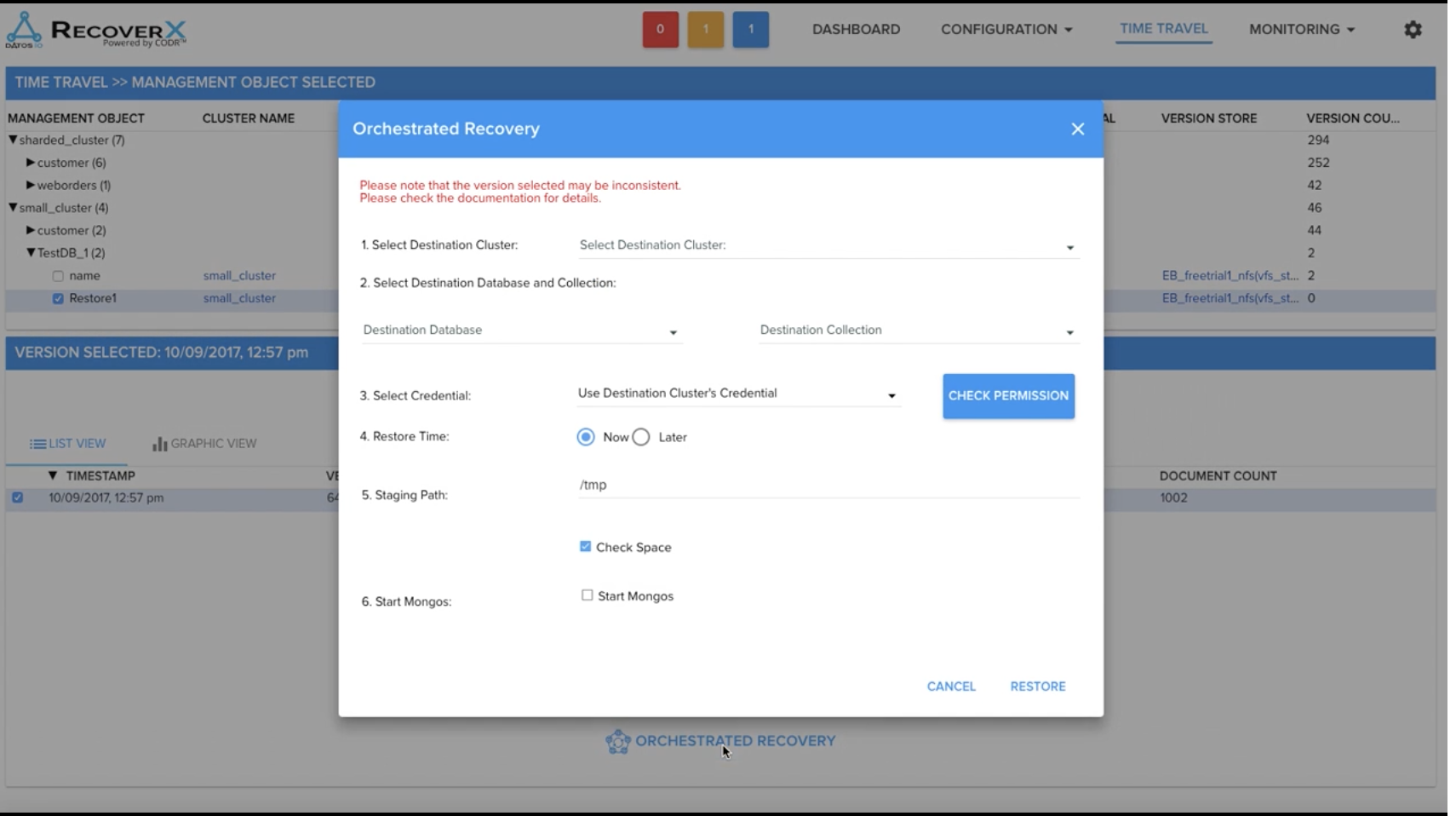
Collections can be recovered to the same MongoDB database or a different instance for test and dev.
RecoverX can be deployed on physical or virtual servers or run in the Public Cloud.